今天又和Redis超时杠上了
摘要:究竟是不是cpu占比高的问题导致redis超时的呢?
本文分享自华为云社区《我又和redis超时杠上了》,作者:蓝胖子的编程梦 。
背景
经过上次redis超时排查,并联系云服务商解决之后,redis超时的现象好了一阵子,但是最近又有超时现象报出,但与上次不同的是,这次超时的现象发生在业务高峰期,在简单看过服务器的各项指标以后,发现只有cpu的使用率在高峰期略高,我们是8核cpu,高峰期能达到90%的使用率,其余指标都相对正常。
但究竟是不是cpu占比高的问题导致redis超时的呢?还有待商榷,因为cpu调度程序慢本质上也是个概率性事件。
解决思路
略带侥幸的联系云服务商
有了上次的经验过后,我也是联系了云服务商那边也排查下是否还存在上次超时的原因,但其实还是有直觉,这次的原因和上次超时是不一样的(备注:上次超时是由于云服务商那边对集群的流量隔离做的不够好,导致其他企业机器流量影响到了我们的机器,且发生在业务低峰期),这次发生在业务高峰期。
果然,云服务商得出的结论也是之前出问题的机器以及迁移走了,并且他们也和我同时展开排查。
抓包分析
在ecs服务器上进行抓包,当出现超时时,关闭tcpdump进行分析。
tcpdump 漏包了?
在dump下抓包文件后,经过wireshark分析,并没有发现丢包信息,想着应该是tcpdump漏包了。
tcpdump 出现漏包的情况
[webserver@hw-sg1-test-0001 ~]$ sudo tcpdump -i eth0 tcp port 6379 -w p.cap -W 2 -G 3600 -C 2000 tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
可以看到默认的抓包大小262144 bytes,在业务高峰期如果每个包最大长度都在这个值,很可能就导致缓冲区满了,而之前一次抓包分析为什么就没有这个问题呢,因为那是在业务低峰期,tcpdump丢包概率比较小。
sudo tcpdump -i eth0 tcp port 6379 -w p5.cap -W 2 -G 3600 -C 2000 tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes ^C147940 packets captured 468554 packets received by filter 318544 packets dropped by kernel
packets dropped by kernel 说明tcpdump丢弃了某些包,因为tcpdump在处理包时,是先将包放到一个缓冲区进行分析,当缓冲区满的时候会直接进行丢弃,这样导致我在用wireshark分析包的时候,就会出现有些包找不到的情况。
在缩小抓取的包大小和去掉域名解析后,不再漏包了。
[webserver@hw-sg1-backend-0003 ~]$ sudo tcpdump -i eth0 tcp port 6379 -w p5.cap -W 2 -G 3600 -C 2000 -n -s 1520 tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 1520 bytes ^C21334 packets captured 21454 packets received by filter 0 packets dropped by kernel
抓包分析超时情况
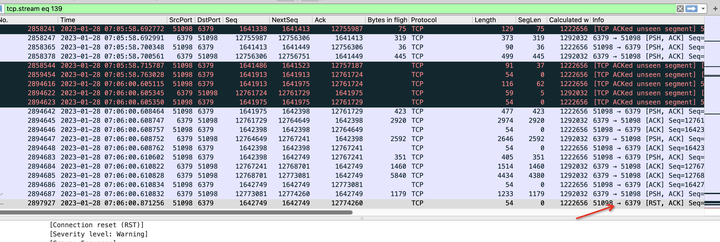
redis客户端超时时间设置的200ms,可以看到2894687号包是redis服务器发送给客户端的包,然后2897927是客户端发送给redis服务端的rst,正常情况客户端收到redis服务端的psh信号的包应该会回复一个ack的,但是客户端却在200ms以后回复了一个rst,说明了什么问题?
我们的客户端是golang写的,可以想到的情况是,客户端程序在读取包过程协程会有切换上下文操作,当客户端发现有可读包时并切回go协程的时候,会首先判断当前读操作是否超时,如果超时,则直接调用close方法关闭连接了。
那么close方法是发送rst信号吗,正常不应该是fin信号?
非也,close方法如果关闭的时候,连接读缓冲区的数据还有未被应用程序读取的话,那么此时close方法的调用会发送rst信号。
可见,问题的确是出在客户端了,并且看上去像是客户端来不及读取服务端的消息。看到这里,其实我心里已经百分之八九十确定是cpu的使用率达到瓶颈了。
云服务商来信了
在分析到上一个步骤的时候,云服务商告诉我,他们知道原因了,是ecs服务的磁盘吞吐量达到瞬时上线,说故障点是和超时的故障点是吻合的。
我知道这个后,第一时间的疑惑是,为啥磁盘吞吐会影响到网络传输,云服务商给的解释是磁盘吞吐达到瞬时上线后,对服务整体是有影响的,我又看了下ecs的监控图标,发现监控图标显示的磁盘吞吐远远没有云服务商提到的那么多。

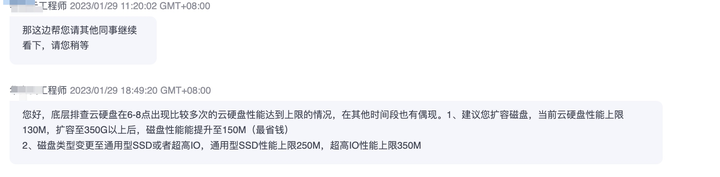
尽管云服务商坚持是磁盘iops达到了上限,但还是不能说服我 磁盘的iops瞬时上限会那么大影响到网络传输。
于是有了接下来第二天的抓包分析。
第二天的抓包分析
基于对昨天的分析,我怀疑到了cpu头上,如果cpu切换进程缓慢,协程调度缓慢,那么的确是有可能发生超时的。由于目前的监控缺少对协程调度延迟的监控,所以决定加上这一指标。
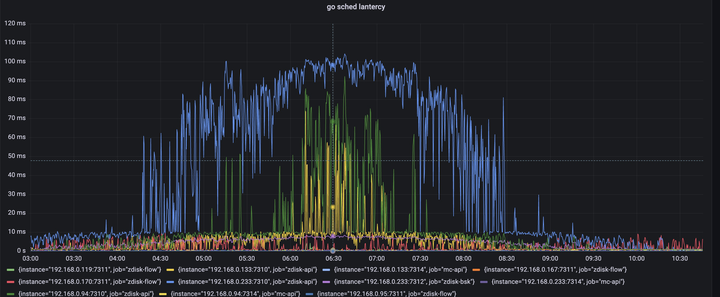
golang1.17后 runtime包提供了协程调度延迟的直方图统计信息,而go prometheus的client其实以已经支持将这个信息转换为prometheus内置的指标类型,metric名称是go_sched_latencies_seconds,而我们之前试用prometheus的client包注册的collector 是兼容到go1.16以及之前的版本,所以没有当改用到最新的collector后,client如期返回了go_sched_latencies_seconds 直方图信息。
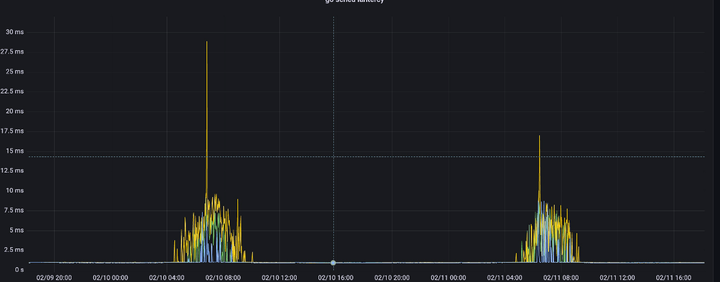
将这个信息展示在grafana里。于是有了第二天协程调度延迟的信息。p999在业务高峰期间达到了100ms,也是与超时时间吻合的。协程调度延迟指的是协程变为可运行状态后到被真正执行这段时间等待被调度的时间,这里都高达100ms了,如果加上cpu线程,进程切换上下文时间,很有可能是超过了redis client端设置的200ms超时上限。
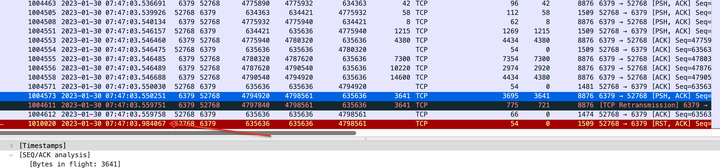
为了排除掉是磁盘原因引起的超时。
我在7点又进行了抓包分析,发现和昨天抓到包的情况是一致的,客户端最后来不及回应服务端的包最后发送rst了。
然后看了下此时机器磁盘吞吐情况,发现图中箭头处也处于高峰期,但是磁盘吞吐量并未上去,而升上去的点正是抓包带来的,怀疑是抓包写入文件导致磁盘吞吐量涨上去了。于是又问了服务商要磁盘达到瞬时峰值的日志。
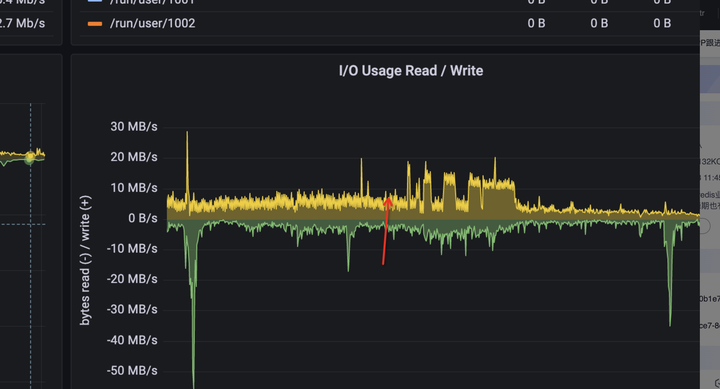

发现报瞬时峰值的日志也和抓包时间吻合,所以已经确认磁盘吞吐达到上限是抓包导致的,网络超时是和磁盘吞吐无关的,反而应该是cpu使用率达到上限了,虽然没有100%,也是8核,但毕竟cpu某个核达到上限是概率性事件,而对于redis这种时延敏感性应用,一但发生,那么超时是有可能的。
完美解决
于是,在业务低峰期将我们三台ecs服务进行了cpu配置提升,提升后效果很明显,超时在高峰期不见了,协程调度延迟也大大减少。
总结
1,对于抓包分析,还是疏忽了,加上包限制大小,能很好的防止tcpdump抓包时丢包的情况。
2,对于任何第三方的说法要有自己的判断力,像这次如果中途去将磁盘扩容显然是不能解决问题的。
3,性能问题分析真是像一个侦探破案的过程,不断列出证据,不断排除掉干扰因素,不断论证的过程也是性能分析的魅力所在吧,就像这次看到cpu的确比较高了,但是究竟是不是客户端问题呢?我又抓包论证了的确是客户端问题,那究竟是不是协程调度问题呢?我又列出协程调度延迟。